Main Guide¶
Author: Clarence Mah | Last Updated: Dec 23, 2024
Here we will analyze a subset of the U2-OS cell dataset from the Bento paper, in which 130 genes and 5 non-targeting controls are spatially profiled with MERFISH. The full dataset includes 1153 cells, each with cell/nuclear segmentation masks and 2D transcript coordinates. Here we demonstrate Bento’s key functionality on a representative subset.
Setup¶
Load libraries used in this analysis.
%load_ext autoreload
%autoreload 2
import bento as bt
import spatialdata as sd
import matplotlib.pyplot as plt
Load Data¶
Download the MERFISH dataset from the Bento paper at this link and unzip it to data.zarr.
The loaded object is a SpatialData object, a container for spatial omics data. Under the hood, the SpatialData framework reads/writes data from/to disk and provides a unified interface in Python.
Note
See Data Format for more details.
sdata = sd.read_zarr("/mnt/d/mah2024_merfish/data.zarr/")
sdata
SpatialData object, with associated Zarr store: /mnt/d/mah2024_merfish/data.zarr
├── Points
│ └── 'transcripts': DataFrame with shape: (<Delayed>, 5) (2D points)
├── Shapes
│ ├── 'cell_boundaries': GeoDataFrame shape: (1153, 1) (2D shapes)
│ └── 'nucleus_boundaries': GeoDataFrame shape: (1153, 1) (2D shapes)
└── Tables
└── 'table': AnnData (1153, 135)
with coordinate systems:
▸ 'global', with elements:
transcripts (Points), cell_boundaries (Shapes), nucleus_boundaries (Shapes)
with the following elements in the Zarr store but not in the SpatialData object:
▸ table (Table)
sdata = sd.bounding_box_query(
sdata,
axes=["x", "y"],
min_coordinate=[0, 0],
max_coordinate=[6000, 6000],
target_coordinate_system="global",
)
sdata = bt.io.prep(sdata)
Visualize Data¶
Let’s visualize the data to gain a better intuition for the dataset. Spatial plotting functions in bento-tools automatically render cell and nuclear boundaries by default. We then overlay the transcript density on top with bt.pl.density().
Tip
See the spatial plotting guide for more details.
plt.figure(figsize=(10, 10))
bt.pl.density(sdata)

Keep genes where at least 10 molecules are detected in at least one cell.
sdata = bt.ut.filter_by_gene(sdata, min_count=10)
Spatial summary statistics¶
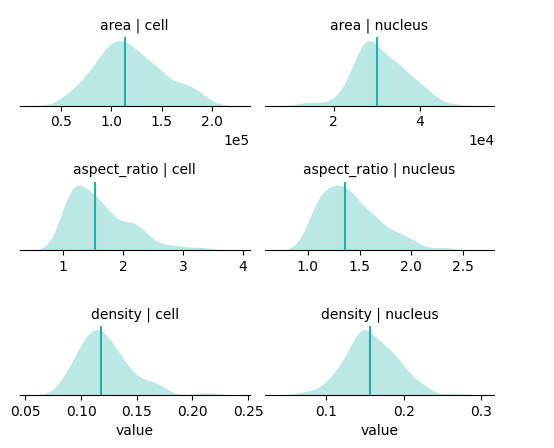
You can get a quick summary of cell and nuclear properties, including area, shape i.e. aspect ratio, and RNA density. This is an easy way to assess data quality and manage outliers e.g. cells with an extreme number of transcripts, very small area (possibly segmentation artifacts), no nuclei, etc.
See also
See the spatial features tutorial for additional metrics.
bt.tl.shape_stats(sdata)
bt.pl.shape_stats(sdata)
RNAflux: semantic segmentation of subcellular domains¶
RNAflux first quantifies subcellular expression gradients at pixel resolution before identifying consistent subcellular domains via unsupervised clustering. The result is a semantic segmentation of the cell, where each pixel is assigned to a subcellular domain. For the purposes of this tutorial, we will lower the resolution res parameter to speed up computation.
Tip
The embedding is calculated at 10% unit resolution for speed. Higher resolution trades off speed for smoother embeddings. Note that computation time scales quadratically \(O(res^{2})\) in relation to resolution \(res\) e.g. 10% is 100x faster than 100% resolution.
Learn more about the algorithm here.
res = 0.1
bt.tl.flux(sdata, method="radius", res=res, recompute=True)
bt.tl.flux() also performs dimensional reduction using PCA and saves the first 10 principal components (PCs). We can visualize each pixel as the first 3 PCs mapped to RGB values (red = PC1, green = PC2, and blue = PC3) and scale alpha by the RNA density.
fig, ax = plt.subplots(figsize=(12, 12))
bt.pl.flux(sdata, res=res, ax=ax)

Identify subcellular domains¶
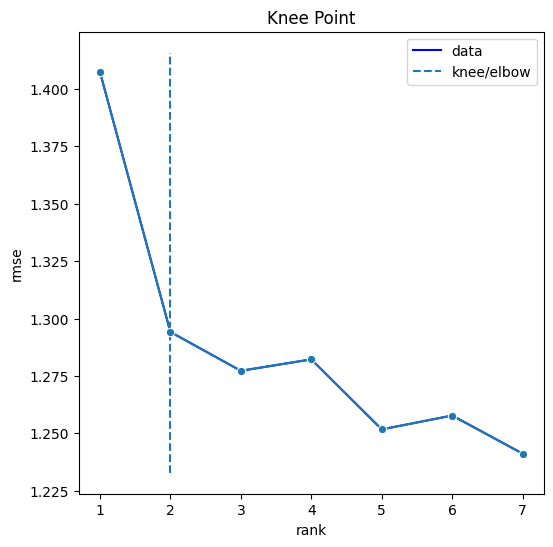
To identify distinct subcellular domains in a data-driven manner, we can cluster pixels by their RNAflux embeddings. The bt.tl.fluxmap() function fits a self-organizing map (SOM) to the reduced PCA space for a range of cluster numbers. We use the elbow method heuristic to recommend the optimal number of clusters. By default, a line plot will be rendered showing the model fit error for each cluster number and draw a vertical dotted line indicating the recommended number.
Tip
Determining the number of clusters is not trivial and can be highly subjective. Occasionally, no number is suggested. You can either try a wider range of cluster numbers or manually pick one. We generally recommend settling on a smaller number of clusters i.e. less than 10 for interpretability.
bt.tl.fluxmap(sdata, res=res, min_count=100, plot_error=True)
Now let’s visualize the predicted subcellular domains. Notice how every cell contains instances of each domain (denoted by the different colors).
fig, ax = plt.subplots(figsize=(12, 12))
bt.pl.fluxmap(sdata, palette=bt.colors.bento6, ax=ax)

fluxmap_names = [s for s in sdata.shapes.keys() if s.startswith("fluxmap")]
bt.tl.comp(
sdata,
points_key="transcripts",
shape_names=fluxmap_names,
)
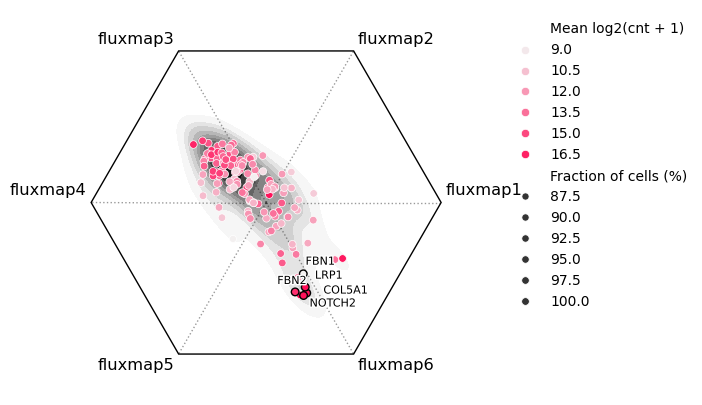
bt.pl.comp(sdata, annotate=5)
No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
Adjusting text positions...
Functional enrichment of fluxmaps¶
We can utilize RNAflux embeddings to compute enrichment scores across the entire area of each cell. Given the appropriate genesets, they can help us identify functionally relevant domains such as organelles and subcellular compartments e.g. the nucleus and cytoplasm. Here we employ published APEX-seq data measuring the relative expression (log2 fold change) of genes in various compartments. We can compare geneset enrichment scores to the fluxmaps.
bt.tl.fe_fazal2019(sdata, batch_size=50000)
113 samples of mat are empty, they will be removed.
Running wsum on mat with 182101 samples and 135 targets for 8 sources.
You can visualize functional enrichment scores with bt.pl.fe() as well as specific shapes to overlay. In this case, we showcase the striking correspondence of the “Nucleus” enrichment with one of the fluxmaps.
plt.figure(figsize=(12, 12))
bt.pl.fe(
sdata,
"flux_Nucleus",
cmap="Reds",
res=res,
vmin=0,
)

Predict RNA Localization Patterns¶
We will use the RNAforest model, to predict and annotate subcellular localization patterns. A single “sample” refers to the set of points corresponding to a given gene in a single cell. In the case that every cell expresses every gene, the number of samples is at most \(n * m\) for \(n\) cells and \(m\) genes.
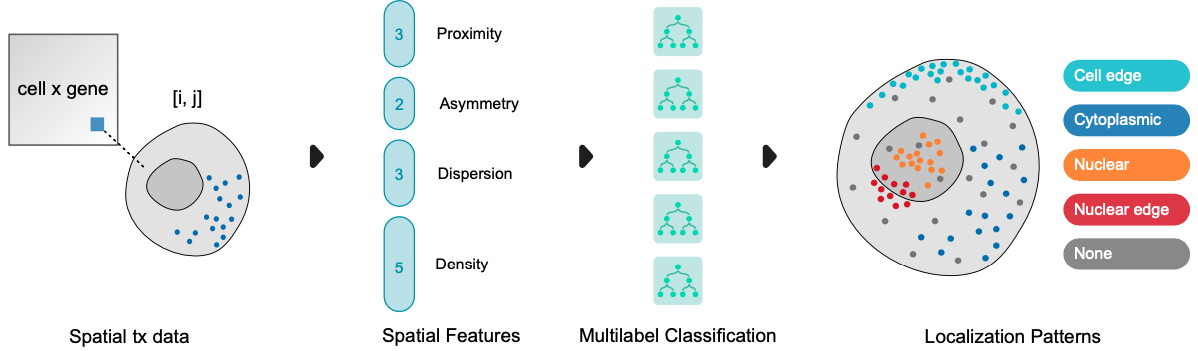
The five subcellular patterns we can predict are:
cell edge: near the cell membrane
cytoplasmic: mostly outside the nucleus in the cytoplasm
nuclear: most in the nucleus
nuclear edge: near the nuclear membrane, either
none: none of the above patterns, more or less randomly distributed
See also
See more details about the spatial statistics used as input features for classification.
bt.tl.lp(sdata)
Done 🍱
Done 🍱
We can view the observed pattern frequencies to get a rough idea of how transcripts are localizing.
bt.pl.lp_dist(sdata)

We can also visualize the localization of each gene where the point position denotes the balance between subcellular localization pattern frequencies. The color denotes the gene’s most frequent pattern. Interestingly, we see a wide range of variability in localization. A large number of genes are pulled towards none while nuclear enriched genes show strong bias and a high fraction of cells.
bt.tl.lp_stats(sdata)
bt.pl.lp_genes(sdata, sizes=(10, 85), size_norm=(90, 100))
WARNING:matplotlib.legend:No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.

Colocalization analysis¶
Here we use the Colocation Quotient or CLQ (Leslie & Kronenfeld, 2011) to measure pairwise colocalization between genes. Given two sets of points, A and B, the CLQ is the ratio of observed to expected proprtion of B among A’s neighbors.
At the same time, we quantify colocalization in a compartment-specific manner i.e. transcripts in the nucleus organize differently than they do in the cytoplasm.

First lets create shapes for the cytoplasm.
bt.geo.overlay(
sdata,
s1="cell_boundaries",
s2="nucleus_boundaries",
name="cytoplasm",
how="difference",
)
Now we can calculate CLQ values for every gene pair – one for the cytoplasm and once more for the nucleus.
bt.tl.coloc_quotient(sdata, shapes=["cytoplasm", "nucleus_boundaries"])
We can represent the data as a 3-dimensional tensor: compartments, cells, and gene pairs and apply tensor decomposition - in this case, non-negative PARAFAC (Shashua & Hazan 2005) - to discover substructure considering cell and compartment-specific patterns.
The data tensor is broken down into \(k\) factors. When added together, the factors reconstruct the original data tensor with some degree of error. By plotting the error for each \(k\) rank decomposition, we can use the elbow method heuristic to recommend the optimal number of factors.
bt.tl.colocation(sdata, ranks=range(1, 6))
Preparing tensor...
:running: Decomposing tensor...
:heavy_check_mark: Done.
Let’s plot the factor loadings for the suggested \(k = 2\). From left to right, the three heatmaps show the loadings of each factor for each dimension – compartments, cells, and gene pairs. We can limit the heatmap to show the top 5 associated gene pairs for each factor.
bt.pl.colocation(sdata, rank=2)

Since a range of ranks were tested, we can also plot their loadings to examine finer resolution structure in overall colocalization patterns.
bt.pl.colocation(sdata, rank=6)
